本来做过滤的算法时想直接用目标字符串去和每一个关键词匹配,如果关键词少,还好,关键词多之后效率会很低。
所以看了一些博客写了一个算法。记录一下。
目标:
当然,最重要的是能过滤敏感词,但是如果简单的匹配,添加进一些混淆的字符就没法过滤了。所以目标有:
2、处理一些简单的混淆。
3、高效
在敏感词少的情况不谈,如果敏感词多了,词语开头重复的词有很多,例如“尼玛,尼美,尼马*”等等,用一个“我“字去对比,会比较三次,这样检索会大量重复无用的匹配,其实只需要比较一次,怎么实现呢,最好的办法是用敏感词去建树,然后便利树进行匹配。
如果我们有敏感词:中央,中国,中国人,中华人民,美国人,美国,美利坚。
我们需要构建一棵树,如下图:
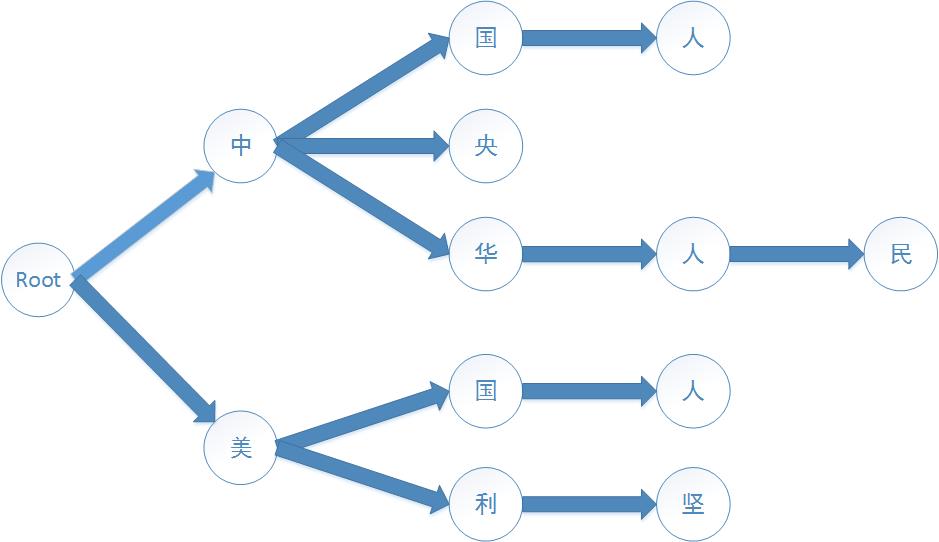
{kind=link}
每个节点还要有一个boolean类型变量用于标记敏感词结尾,例如中国,”国“字节点为结尾,标记true,用途在后面说。
对于完全不匹配的词,我们只需要匹配两次即可,匹配次数与词的数量无关。
我们先定义节点类
|
0 1 2 3 4 5 6 7 8 |
private static class WordNode { private Map<Character, WordNode> childs = null; private boolean isEnd = false; /* 忽略get set方法 */ } |
其中isEnd为是否敏感词结尾标记,childs是子节点集合,childs的key为一个子节点字符,value为一个子节点。
定义好节点,现在来创建树:
定义根节点:
|
0 1 2 3 |
private WordNode root = null; |
构建树
流程图:
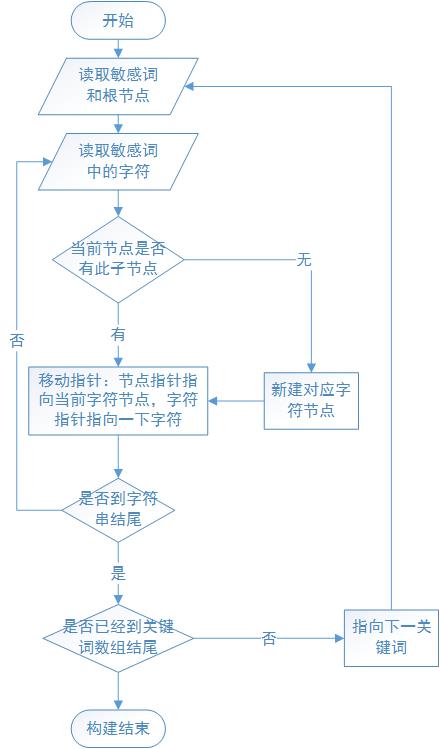

|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
/** * 构建关键词树 * * @param words * 要过滤的词语集合 */ public void init(String [] words) { // 创建根节点 root = new WordNode(); // 遍历每一个关键词,依次添加到树 for(String keyword : words) { // 创建节点“指针”,用于便利树 WordNode tempNode = root; /** * 取出词组的每一个字,从根节点开始深度遍历检索,如果不存在则添加新的节点 */ char[] chars = keyword.toCharArray(); for( int i = 0; i < chars. length; i++) { char c = chars[ i]; // 如果此层节点集合为null,创建集合 if( tempNode.getChilds() == null) { tempNode.setChilds( new HashMap<Character, WordNode>()); } // 尝试获取子节点c WordNode nextNode = tempNode.getChilds().get( c); // 如果不存在c节点,创建此节点 if( nextNode == null) { WordNode newNode = new WordNode(); tempNode.getChilds().put( c, newNode); nextNode = newNode; } // ”指针“移到c(下一)节点 tempNode = nextNode; // 如果已经遍历到结尾,为C节点添加结尾标记 if( i == chars. length -1) { tempNode.setEnd( true); } } } } |


|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
/** * * @param str * 目标字符串 * @return * 匹配结果 */ public Map<Integer, Integer> find(String str) { // 用于记录关键词位置 Map<Integer, Integer> filterWord = new HashMap<Integer, Integer>(); // 转换(繁简,全半等) char[] chars = translation( str); int start = 0; // 遍历每一个字符 while( start < chars. length) { // 从根节点开始匹配 WordNode node = root; // 记录匹配的字符串长度 int length = 0; // 寻找等一个匹配的字符 while( start < chars. length && !node.getChilds().containsKey( chars[ start])) { start++; } // 记录第一个匹配字符是英文还是中文 boolean isChinese = false; boolean isEnglish = false; if( start < chars. length) { if( isChinese( chars[ start])) isChinese = true; if(isAlphabet( chars[ start])) { isEnglish = true; } } // 匹配关键词 while( start+ length < chars. length && node.getChilds().containsKey( chars[ start + length])) { // 成功,跳到下一字符 node = node.getChilds().get( chars[ start + length]); length++; // 如果已经到达叶子节点,结束匹配 if( node.getChilds() == null) { break; } // 跳过符号等特殊字符 while(IsSkip( chars[ start+ length]) && start+ length < chars. length) { length++; } // 如果开头是中文,跳过不匹配的非中文字符(过滤“法f$轮 le功”这类词) while( start+ length < chars. length && isChinese && !node .getChilds().containsKey(chars [start +length ])) { if(! isChinese( chars[ start+ length])) { length++; } else { break; } } // 如果开头是英文,跳过不匹配的非英文字符(过滤“f有u32ck”这类词) while( start+ length < chars. length && isEnglish && !node .getChilds().containsKey(chars [start +length ])) { if(!isAlphabet( chars[ start+ length])) { length++; } else { break; } } } // 如果匹配结束,最后匹配的节点是结尾,则匹配成功 if( node.isEnd()) { filterWord.put( start, length); // 跳过已经匹配的词语 start = start + length; } else { // 不匹配,跳到下一个已经字符 start++; } } //返回匹配结果 return filterWord; } |
繁简字体转换:http://618119.com/archives/2010/12/12/186.html
参考代码(C#):http://www.cnblogs.com/passer/p/3461052.html
DFA算法实现:http://blog.csdn.net/chenssy/article/details/26961957
更新:代码中使用了HashMap存储敏感词,如果你添加了addWord和remove等写操作的方法时,在读写高并发时会出现异常,请考虑线程安全的ConcurrentHashMap和读写锁等。
放上完整代码:
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 |
package lee.common; import java.util.HashMap; import java.util.Map; /** * @author 黄冠豪 * @email waiting.hao@gmail.com * @create 2014年11月10日 * */ public class WordFilter { private WordNode root = null; public boolean isInit() { return root != null; } /** * 构建关键词树 * * @param words * 要过滤的词语集合 */ public void init(String [] words) { // 关键词树 TODO 线程锁 // 创建根节点 root = new WordNode(); // 遍历每一个关键词,依次添加到树 for(String keyword : words) { // 创建节点“指针”,用于便利树 WordNode tempNode = root; /** * 取出词组的每一个字,从根节点开始深度遍历检索,如果不存在则添加新的节点 */ char[] chars = keyword.toCharArray(); for(int i = 0; i < chars.length; i++) { char c = chars[i]; // 如果此层节点集合为null,创建集合 if(tempNode.getChilds() == null) { tempNode.setChilds(new HashMap<Character, WordNode>()); } // 尝试获取子节点c WordNode nextNode = tempNode.getChilds().get(c); // 如果不存在c节点,新建此节点 if(nextNode == null) { WordNode newNode = new WordNode(); tempNode.getChilds().put(c, newNode); nextNode = newNode; } // ”指针“移到c(下一)节点 tempNode = nextNode; // 如果已经遍历到结尾,为C节点添加结尾标记 if(i == chars.length -1) { tempNode.setEnd(true); } } } } /** * * @param str * 目标字符串 * @return * 匹配结果 */ public Map<Integer, Integer> find(String str) { // 用于记录关键词位置 Map<Integer, Integer> filterWord = new HashMap<Integer, Integer>(); // 转换(繁简,全半等) char[] chars = translation(str); int start = 0; // 遍历每一个字符 while(start < chars.length) { // 从根节点开始匹配 WordNode node = root; // 记录匹配的字符串长度 int length = 0; // 寻找等一个匹配的字符 while(start < chars.length && !node.getChilds().containsKey(chars[start])) { start++; } // 记录第一个匹配字符是英文还是中文 boolean isChinese = false; boolean isEnglish = false; if(start < chars.length) { if(isChinese(chars[start])) isChinese = true; if(isAlphabet(chars[start])) { isEnglish = true; } } // 匹配关键词 while(start+length < chars.length && node.getChilds().containsKey(chars[start + length])) { // 成功,跳到下一字符 node = node.getChilds().get(chars[start + length]); length++; // 如果已经到达叶子节点,结束匹配 if(node.getChilds() == null) { break; } // 跳过符号等特殊字符 while(IsSkip(chars[start+length]) && start+length < chars.length) { length++; } // 如果开头是中文,跳过不匹配的非中文字符(过滤“法f$轮le功”这类词) while(start+length < chars.length && isChinese && !node.getChilds().containsKey(chars[start+length])) { if(!isChinese(chars[start+length])) { length++; } else { break; } } // 如果开头是英文,跳过不匹配的非英文字符(过滤“f有u32ck”这类词) while(start+length < chars.length && isEnglish && !node.getChilds().containsKey(chars[start+length])) { if(!isAlphabet(chars[start+length])) { length++; } else { break; } } } // 如果匹配结束,最后匹配的节点是结尾,则匹配成功 if(node.isEnd()) { filterWord.put(start, length); // 跳过已经匹配的词语 start = start + length; } else { // 不匹配,跳到下一个已经字符 start++; } } //返回匹配结果 return filterWord; } private boolean IsSkip(char firstChar) { if (firstChar < '0') return true; if (firstChar > '9' && firstChar < 'A') return true; if (firstChar > 'Z' && firstChar < 'a') return true; if (firstChar > 'z' && firstChar < 128) return true; return false; } private boolean isAlphabet(char c) { if (c < 'Z' && c > 'a') return true; else return false; } private static boolean isChinese(char c) { Character.UnicodeBlock ub = Character.UnicodeBlock.of(c); if (ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS || ub == Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS || ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A || ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_B || ub == Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION || ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS || ub == Character.UnicodeBlock.GENERAL_PUNCTUATION) { return true; } return false; } /** * 预处理 * @param str * @return */ private char[] translation(String str) { char[] chars = str.toCharArray(); for(int i = 0; i < chars.length; i++) { char c = chars[i]; // 全部转小写 if (Character.isUpperCase(c)) chars[i] = Character.toLowerCase(c); // 全角转半角 if (c > 0xFF00 && c < 0xFF5F) chars[i] = (char)(c - 0xFEE0); // 全角空格 if(c == 0x4CC) { chars[i] = ' '; } if(CharTranslation.isCht(c)) { chars[i] = CharTranslation.cht2chs(c); } } return chars; } /** * 树节点 * @author 黄冠豪 * @create 2014年11月10日 * */ private static class WordNode { private Map<Character, WordNode> childs = null; private boolean isEnd = false; public boolean isEnd() { return isEnd; } public void setEnd(boolean isEnd) { this.isEnd = isEnd; } public Map<Character, WordNode> getChilds() { return childs; } public void setChilds(Map<Character, WordNode> childs) { this.childs = childs; } } } |